
AI-Powered Web Scraping: The Future of Data Extraction
Explore how AI is revolutionizing web scraping, making it more efficient, accurate, and accessible for businesses and individuals.


What is an AI Web Scraper?
AI web scrapers use artificial intelligence and machine learning to automate data extraction from websites. Unlike traditional scrapers that rely on predefined rules, AI-powered tools adapt to changing layouts and handle dynamic content more effectively.
Comparing Traditional vs. AI Web Scraping Techniques
To grasp AI's impact on web scraping, we must compare conventional methods with AI-driven approaches. Let's examine how these two techniques differ in execution and capabilities.
How Traditional Web Scraping Works
Conventional web scraping uses a structured approach to extract website data. The process typically involves:
Identify the Target Website
Choose the website you want to scrape data from. This could be an e-commerce site, news portal, or any other web resource with the information you need.
Analyze the Website Structure
Examine the HTML structure of the web pages. Inspect the source code to identify relevant HTML tags, classes, or IDs containing the desired data.
Choose a Scraping Tool or Library
Select an appropriate tool or programming library for web scraping. Popular options include Beautiful Soup or Scrapy for Python, or specialized software like Octoparse.
Write the Scraping Script
Develop a script to navigate target pages and extract required data. This typically involves:
- Sending HTTP requests to the website
- Parsing HTML content
- Locating desired elements using selectors (e.g., CSS or XPath)
- Extracting data from these elements
Handle Pagination and Navigation
Implement logic to navigate through multiple pages if data is spread across different pages or requires website interaction.
Clean and Structure the Data
Process extracted data to remove irrelevant information and structure it in a usable format (e.g., CSV, JSON, or database entries).
Implement Error Handling and Retries
Add mechanisms to handle potential errors, such as network issues or website structure changes. Include retry logic for failed requests.
While effective for many scenarios, this traditional approach often requires manual updates when websites change their structure. AI-powered scraping offers significant advantages in this regard.
How AI Web Scraping Works
AI web scraping leverages machine learning models to adapt to website structure changes and extract data more efficiently. Here's how AI web scraping typically works using a Large Language Model (LLM):
Select an Appropriate LLM
Choose an LLM based on your specific needs, considering:
- Model type: Open-source (e.g., LLAMA 3.1) or closed-source (e.g., GPT-4 or Claude 3.5 Sonnet)
- Cost: Compare pricing for input and output tokens, especially for closed-source models
- Processing speed: Evaluate token throughput for scraping efficiency
- Input capacity: Consider the context window for handling large web pages
Balance these factors to find the best LLM for your web scraping project.
Input Web Page Content
Feed the target web page's HTML content into the LLM. Use raw HTML, processed content, or preferably, a Markdown representation. Markdown maintains content structure while using fewer tokens, improving LLM processing efficiency.
Craft Prompts
Design specific prompts to guide the LLM on data extraction and output format. For example: "Extract the product name, price, and description from this e-commerce page."
Generate Structured Output
The LLM processes the input and creates structured output based on the prompt. This could be in JSON, CSV, or another specified format.
Validate and Clean Data
Implement post-processing logic to clean and validate the LLM's output, ensuring it meets quality standards and required formats.
This AI-driven approach offers greater flexibility and adaptability than traditional web scraping methods, handling diverse web page structures and content types more effectively.
Comparing AI and Traditional Web Scraping: Features and Limitations
Now that we've explored how AI web scraping works, let's delve into how it compares to traditional methods. AI is revolutionizing web scraping, and understanding these differences is crucial. This section explores key features, advantages, and limitations of both approaches, highlighting AI's transformative impact on data extraction.
Key Features and Advantages of AI Web Scraping
AI web scraping offers superior adaptability, dynamic content handling, and contextual understanding compared to traditional methods.
| Feature | Traditional Web Scraping | AI Web Scraping |
|---|---|---|
| Adaptability | Uses predefined rules; fails when layouts change | Adapts to changes dynamically |
| Accuracy | Scrapes exactly what was pre-defined in rules | Filters out irrelevant data, ability to understand data context |
| Data Processing | Limited complex data processing | Efficiently cleans, processes, and transforms data on the fly; performs classification and summarization tasks |
| Contextual Understanding | Limited to predefined extraction rules | Understands data context, distinguishes information types |
| Maintenance | Requires constant updates | Learns and adapts over time, reducing manual intervention |
| Setup Costs | Manual coding of rules needed | Simple instructions for extraction needed |
Key Limitations of AI Web Scraping
While AI web scraping offers significant advantages in adaptability and data processing, it comes with challenges in initial setup, resource requirements, precision control, and data privacy considerations compared to traditional methods.
| Limitation | Traditional Web Scraping | AI Web Scraping |
|---|---|---|
| Resource Requirements | Lower computational needs | Higher computational demands, potentially costlier for big scraping tasks with loads of tokens |
| Precision | Allows pinpointing and extracting exact data points | Sometimes challenging to steer and force extraction of specific information |
| Data Privacy | Limited data collection | May collect sensitive information, raising privacy concerns |
How to get started with AI web scraping
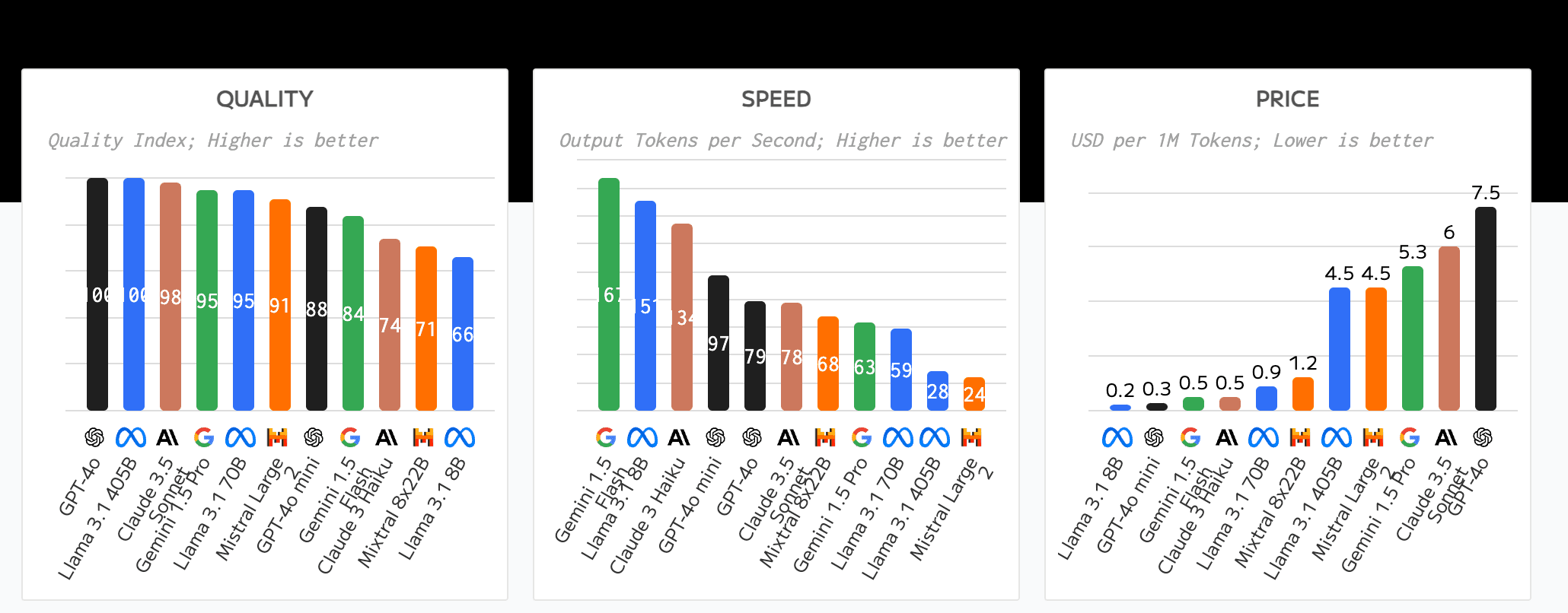
Selecting the Best Model
When selecting the best model for AI web scraping, cost, context window size, and rate limits are key factors to consider.
-
Cost: The financial aspect of using AI models can significantly impact your choice. More advanced models often come with higher costs, which need to be balanced against the value they provide.

-
Token Context: The context window size of the model is critical. Larger context windows allow for processing more text at once, which can be beneficial for complex web pages or when scraping multiple pages simultaneously. However, larger contexts also typically mean higher costs and potentially slower processing times.
Model Provider Model Name Context Window OpenAI GPT-4o 128,000 OpenAI GPT-4o mini 128,000 Google Gemini 1.5 Pro 2,000,000 Google Gemini 1.5 Flash 1,000,000 Meta Llama 3.1 Instruct 405B 128,000 Meta Llama 3.1 Instruct 70B 128,000 Meta Llama 3.1 Instruct 8B 128,000 Mistral Mistral Large 2 128,000 Anthropic Claude 3.5 Sonnet 200,000 Anthropic Claude 3 Opus 200,000 Anthropic Claude 3 Sonnet 200,000 Anthropic Claude 3 Haiku 200,000 -
Rate Limits and Tokens per Second: The speed at which a model can process tokens (tokens per second) and any rate limits imposed by the API provider are important considerations. These factors affect how quickly you can scrape large amounts of data and how many requests you can make within a given timeframe.

Balancing these factors is essential to choose a model that meets your specific web scraping needs while remaining cost-effective and efficient. For instance, while GPT-4o offers a large context window and high accuracy, it may be overkill for simple scraping tasks where a more economical model like GPT-4o-mini could suffice.
Consider your project's specific requirements, budget constraints, and the complexity of the websites you're scraping when making your selection. It's often beneficial to start with a more modest model and scale up if needed, rather than immediately opting for the most powerful (and expensive) option available.
Scraping Webpages and Converting to Markdown
When it comes to AI web scraping, converting webpages to markdown format offers several advantages:
-
Simplified Structure: Markdown provides a clean, easy-to-read format that strips away complex HTML elements, making it ideal for LLM processing.
-
Reduced Noise: By converting to markdown, unnecessary styling and scripting are removed, allowing LLMs to focus on the core content.
-
Consistency: Markdown offers a standardized way to represent headings, lists, and other structural elements across different websites.
-
Lightweight: Markdown files are typically smaller than their HTML counterparts, reducing storage and processing requirements.
-
LLM-Friendly: Many LLMs are trained on or optimized for markdown-like formats, potentially improving their performance on such inputs.
Let's explore three popular tools that can help you convert webpages to markdown for AI web scraping:
1. Jina AI Reader
Jina AI Reader offers a simple yet powerful solution for converting web content to LLM-friendly formats.
Key Features:
- Easy integration by prepending
r.jina.ai/to any URL - Supports both URL reading and web search functionality
- Offers image captioning for enhanced context
- Provides flexible output formats, including clean text and JSON
- Free to use with optional API key for higher rate limits
2. FireCrawl

FireCrawl is a powerful web scraping tool designed specifically for AI-powered data extraction.
Key Features:
- Seamless integration with popular AI models like GPT-4 and Claude
- Supports both single-page scraping and multi-page crawling
- Handles JavaScript-rendered content effectively
- Offers customizable output formats, including JSON and CSV
- Provides a user-friendly interface for creating and managing scraping tasks
- Scalable infrastructure to handle large-scale scraping projects
- Built-in proxy management to avoid IP blocks
3. Markdowner
Markdowner is a simple tool for converting web pages to Markdown format.
Key Features:
- Free to use and easy to self-host
- Easy to use: Just make a GET request to
https://md.dhr.wtf/?url=YOUR_URL - Offers LLM filtering to remove unnecessary information
- Provides detailed markdown mode for comprehensive content
- Supports auto-crawling of up to 10 subpages without needing a sitemap
- Flexible response types: plain text or JSON (controlled via Content-Type header)
Converting Markdown to Structured Data
Once you've converted web content to Markdown, the next step is often to extract structured data from it. This is where LLM function calling comes into play. Function calling is a powerful capability that allows large language models to interact with external tools and APIs by generating structured outputs. For data scraping, this means LLMs can parse unstructured text and output data in predefined formats, generate API calls to scrape web services, execute multi-step scraping workflows, and even help with data cleaning and normalization.
To implement function calling for data scraping, you define functions representing your scraping operations, prompt the LLM with the user's request and function definitions, and then use the LLM's structured output (typically JSON) to execute the actual scraping operation. This approach creates more flexible and powerful data scraping tools that can understand natural language instructions and adapt to various data sources and formats, significantly enhancing the capabilities of AI-powered web scraping solutions.
There are several libraries that can help you with function calling:
| Library | GitHub Stars | Programming Language | Description |
|---|---|---|---|
| LangChain | 65.4k | Python, JavaScript | A popular framework for developing applications powered by language models. It includes tools for function calling and allows integration with various LLMs. |
| Vercel AI SDK | 4.8k | JavaScript, TypeScript | Provides a set of tools for building AI-powered user interfaces, including support for function calling with various AI models. |
| Instructor | 6.9k | Python | A library for structured outputs from language models. It simplifies the process of extracting structured data from LLM responses, which is closely related to function calling. |
These libraries provide various approaches to implementing function calling with LLMs, from comprehensive frameworks like LangChain to more specialized tools like Instructor. The choice of library depends on your specific requirements, preferred programming language, and the LLM provider you're using.
Use Cases for AI Web Scraping
AI-powered web scraping offers versatile solutions for a wide range of data extraction needs. It excels in two key scenarios:
-
Quick, on-the-go scrapes: AI web scraping tools are perfect for rapid, ad-hoc data extraction tasks. Whether you need to quickly gather information from a single webpage or perform a small-scale scrape, AI-powered tools can swiftly analyze the content and extract relevant data without requiring extensive setup or coding.
-
Scraping diverse, unstructured websites: Traditional web scraping often struggles with websites that lack a consistent structure. AI web scraping shines in these situations, as it can adapt to varying layouts and content structures across different websites. This flexibility makes it ideal for projects that involve extracting data from multiple sources with disparate formats.
No-Code Web Scraping
For those who prefer a no-code approach to web scraping, there are several tools available that simplify the process. One such tool is NoCodeScraper, which offers a user-friendly interface for AI-powered web scraping without requiring any programming knowledge.
Key Features of NoCodeScraper:
- Scraping made Easy and Fast: Simply provide the URL and which fields you want to extract, we cover the rest.
- Zero Coding Experience Required: Dive right in, no coding experience necessary. Just supply the website URL and specify the data you need.
- Unbreakable Resilience: Our robust scraper adjusts and continues to operate effectively, regardless of HTML modifications.
- Universally Compatible: Our technology is equipped to work seamlessly with any new website.
- Hassle-Free Data Export: Simple and flexible data export options in CSV, JSON, or Excel formats.
Curious how it works? Try it out for free.
Effortlessly Extract Data from Your First Website
Simply enter the URL of the website you want to scrape.